A historic moment for GPUs!
On August 23, GPU giant Nvidia released its financial report for the second quarter of 2023, which far exceeded expectations. Overall, Nvidia's revenue in the second quarter reached 13.5 billion US dollars, a 101% increase compared to the same period last year; the net profit reached 6.1 billion US dollars, an 843% increase compared to the same period last year. The astonishing financial report released by Nvidia once caused Nvidia's stock to soar by 6% after the market, and even led to a follow-up increase in many artificial intelligence-related technology stocks after the market.
The main reason for the significant increase in Nvidia's revenue in the second quarter is the current burgeoning trend of artificial intelligence. Since the third quarter of last year, large model technologies represented by ChatGPT have been sought after by almost all Internet companies worldwide, including giants such as Google, Amazon in Silicon Valley, USA, and Baidu, Tencent, Alibaba, and others in China. Behind the training and inference of these large models, artificial intelligence acceleration chips are indispensable, and Nvidia's GPU is currently the preferred solution for the training and inference acceleration of large models. As major technology companies and startups are buying Nvidia's A-series and H-series high-end GPUs in large quantities to support the computing power of large model training, this has also led to a shortage of Nvidia's data center GPUs, which is reflected in the financial report as a surprising increase in revenue and net profit.
Advertisement
In fact, in addition to the dazzling revenue and net profit figures in Nvidia's financial report, there is another key figure worth our attention, which is Nvidia's data center business revenue in the second quarter. According to the financial report, Nvidia's data center business revenue in the second quarter exceeded 10 billion US dollars, a 171% increase compared to the same period last year. The figures of Nvidia's data center business are naturally very astonishing, but if we connect with the relevant income of other companies in the same period and compare, we can see the deeper significance behind this figure. In the same second quarter of 2023, Intel's data center business revenue was 4 billion US dollars, a 15% decrease compared to the same period last year; AMD's data center business revenue was 1.3 billion US dollars, a 11% decrease compared to the same period last year. We can see from this that in terms of data center business revenue, Nvidia's revenue in the second quarter of 2023 has already exceeded the total revenue of Intel and AMD in the same market.
Behind such a comparison, it reflects the reversal of the status of artificial intelligence acceleration chips (GPUs) and general-purpose processor chips (CPUs) in the era of artificial intelligence. At present, in the data center, the most mainstream supplier of artificial intelligence acceleration chips/GPUs is Nvidia, and the two major suppliers of general-purpose processor chips/CPUs are Intel and AMD. Therefore, comparing the revenue figures of Nvidia and Intel+AMD in the data center field is equivalent to comparing the shipment scale between GPUs and CPUs. Although artificial intelligence has been hot since 2016, in the data center, the market share growth of artificial intelligence-related chips compared to general chips CPU is not achieved overnight: before 2023, the share of data center CPUs has always been far higher than that of GPUs; even in the first quarter of 2023, Nvidia's revenue in the data center business (4.2 billion US dollars) was still lower than the total revenue of Intel and AMD in the data center business; in the second quarter, such a power contrast was reversed, and the revenue of data center GPUs once exceeded the revenue of CPUs.
This is also a historic moment. Since the PC era of the 1990s, the CPU has always been the leader of Moore's Law, and its brilliance has continued from the era of personal computers to the era of cloud data centers, and has also promoted the continuous development of the semiconductor field; in 2023, with the impact of artificial intelligence on the entire high-tech industry and human society, the status of CPUs for general computing in the field of semiconductor chips is being replaced by GPUs for artificial intelligence acceleration (and other related artificial intelligence acceleration chips).
The story of Moore's Law is still happening on GPUs.
As we all know, the rise of CPUs is inseparable from the semiconductor Moore's Law. According to Moore's Law, the characteristic size of semiconductor processes evolves every 18 months, and the performance of transistors is greatly improved, which has allowed CPUs to make rapid progress in the golden age of Moore's Law (from the 1980s to the first decade of this century): on the one hand, the performance of CPUs is iterated every year and a half, promoting the emergence of new applications, on the other hand, the emergence of new applications further promotes the demand for CPU performance, thus forming a positive cycle. Such a positive cycle continued until the 2010s, as Moore's Law gradually approached the physical bottleneck and slowly disappeared - we can see that in the past 10 years, the growth rate of CPU performance has gone from a 15% compound annual growth rate in the 1980s and 1990s (i.e., performance doubled every 18 months) to a 3% compound annual growth rate after 2015 (i.e., performance needs 20 years to double).
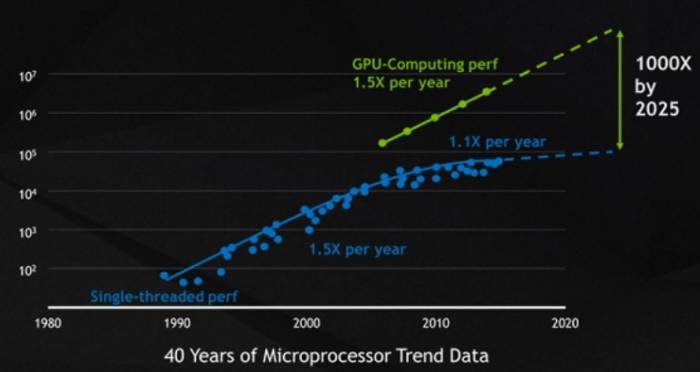
However, although the driving force of Moore's Law for the growth of semiconductor transistor performance has disappeared, the exponential growth of performance predicted by Moore's Law has not disappeared, but has shifted from CPUs to GPUs. If we look at the performance (computing power) growth of GPUs after 2005, we will find that it has in fact been following an exponential growth law, and the performance will double every 2.2 years!Why can GPUs continue to grow exponentially? Here, we can analyze from two aspects: demand and technical support. Demand means whether there is a strong market demand for the exponential growth of GPU performance? And technical support is, is it technically possible to achieve exponential performance growth?
In terms of demand, artificial intelligence does have such a strong demand. We can see that from 2012 (the beginning of the resurgence of neural network artificial intelligence) to now, the computing power demand of artificial intelligence models has indeed been growing exponentially. From 2012 to 2018 was the most popular year for convolutional neural networks. During this period, we saw that the computing power demand of artificial intelligence models grew by about 15 times every two years. At that time, GPUs were mainly responsible for model training, and the performance of GPUs was generally sufficient for inference. However, since 2018, with the advent of the era of large models represented by the Transformer architecture, the evolution of the computing power demand of artificial intelligence models has greatly increased, reaching 750 times every two years. In the era of large models, even the inference of the model cannot be separated from the GPU, and even a single GPU may not be able to meet the demand for inference; training requires hundreds of GPUs to be completed within a reasonable time. In fact, the growth rate of such performance requirements makes the speed at which GPU performance doubles every two years seem inadequate, and in fact, the current speed of GPU performance improvement is still in short supply! Therefore, if we look from the demand side, the curve of exponential growth of GPU performance is expected to continue for a long time, and in the next ten years, GPUs are likely to take over the banner of Moore's Law from CPUs and continue the myth of exponential growth in performance.
Technical support behind the exponential growth of GPU performance
In addition to the demand side, in order to truly maintain the exponential growth of GPU performance, there must be corresponding chip technology support behind it. We believe that in the next few years, there will be three technologies that will be the key to maintaining the exponential growth of GPU performance.
The first technology is domain-specific chip design. The same is a chip, and the performance of GPUs can grow exponentially while CPUs cannot, one of the important factors is that the growth of GPU performance is not only from the improvement of transistor performance and circuit design, but also from the use of domain-specific design ideas. For example, before 2016, the calculations supported by GPUs were mainly 32-bit floating-point numbers (fp32), which is also the default number system in the field of high-performance computing; but after the rise of artificial intelligence, research has shown that artificial intelligence does not need the high precision of 32-bit floating-point numbers, and in fact, 16-bit floating-point numbers are enough for training, and inference can use 8-bit integers or even 4-bit integers. Because the cost of low-precision computing is relatively small, using the idea of domain-specific computing design, and making special optimizations for such low-precision computing can achieve a significant performance improvement in the field of artificial intelligence at a relatively low cost. From the design of Nvidia GPUs, we can see such ideas, we have seen the efficient support of computing number systems from fp32 to fp16 to int8 and int4 in the past 10 years, which can be said to be a low-cost and fast way to improve performance. In addition, there is support for neural networks (TensorCore), support for sparse computing, and hardware support for Transformers, etc., which are all good reflections of domain-specific design on GPUs. In the future, the improvement of GPU performance may come from such domain-specific designs, and the introduction of one or two dedicated acceleration modules can break through the bottleneck of the latest artificial intelligence models and greatly improve overall performance, thus achieving a four-two-thousand effect.
The second technology is advanced packaging technology. The impact of advanced packaging technology on GPUs comes from two aspects: high-speed memory and higher integration. In the era of large models, as the number of model parameters continues to increase, the impact of memory access performance on the overall performance of GPUs is becoming more and more important - even if the GPU chip itself has extremely strong performance, if the memory access speed does not keep up, the overall performance will still be limited by the memory access bandwidth, in other words, it will encounter the "memory wall" problem. To avoid memory access limiting overall performance, advanced packaging is essential. The current high-bandwidth memory access interface (such as the HBM memory interface that has been widely used on data center GPUs) is a standard for advanced packaging, and in the future, we expect to see advanced packaging playing an increasingly important role in memory interfaces, thus promoting the further improvement of GPU performance. Another aspect of advanced packaging in improving GPU performance comes from higher integration. In the most advanced semiconductor processes (such as 3nm and below), as the chip scale increases, the chip yield will face challenges, and GPUs are expected to be the most aggressive chip category in terms of chip scale in the future. In this case, using chiplets to divide a large chip into multiple small chiplets, and using advanced packaging technology to integrate them together, will be one of the important ways for GPUs to break through the chip scale limitations. Currently, AMD's data center GPUs have already used chiplet advanced packaging technology, and Nvidia is expected to introduce this technology in the near future to further continue to improve the integration of GPU chips.
Finally, high-speed data interconnect technology will further ensure the performance improvement of GPU distributed computing. As mentioned earlier, the growth rate of the computing power demand of large models is 750 times every two years, far exceeding the speed at which Moore's Law improves the performance of GPUs. In this way, the performance of a single GPU cannot keep up with the computing power demand of the model, so it must be made up with quantity, that is, the model is divided into multiple GPUs for distributed computing. In the next few years, we can expect to see more and more aggressive distributed computing strategies for large models, using hundreds, thousands, or even tens of thousands of GPUs to complete training. In such large-scale distributed computing, high-speed data interconnects will become key, otherwise, the data exchange between different computing units will become the bottleneck of the overall computing. These data interconnects include short-distance SerDes technology based on electrical interconnects: for example, in Nvidia's Grace Hopper Superchip, NVLINK C2C is used for data interconnect, which can provide a data interconnect bandwidth of up to 900GB/s (equivalent to 7 times that of x16 PCIe Gen5). On the other hand, long-distance data interconnects based on optical interconnects will also become another core technology. When distributed computing needs to use tens of thousands of computing nodes, such long-distance data exchange will also become very common and may become one of the decisive factors for system performance.
We believe that in the era of artificial intelligence, GPUs will further continue the story of Moore's Law and continue the exponential development of performance. To meet the strong demand for performance of artificial intelligence models, GPUs will use core technologies such as domain-specific design, advanced packaging, and high-speed data interconnects to maintain rapid performance improvement, and GPUs and the artificial intelligence acceleration chips they are in will also become the main driving force for technological and market progress in the semiconductor field.
Leave A Comment